This case study illustrates the importance of aligning a graph with the scientific question it should address, the option of filtering signals through a model, and finally the display of a scientific answer in a condensed messaging graph.
Consider a small early development trial, randomized and placebo-controlled (2:1 randomization), with a continuous primary endpoint measured at baseline and longitudinally over a period of 4 weeks. Lower outcome values are better, and there are no dropouts and no missing data. Suppose that the team is interested in the effect of the drug at the last measurement time point, as it is often the case. A common approach in early development trials is to simply plot the observed change scores in a so-called “waterfall plot” such as Figure 1.
ggplot(t4dat, aes(x = sort_id, y = cfb, fill =factor(ztext))) +geom_col(alpha =0.8) +scale_fill_brewer(palette ="Dark2", name ="Treatment") +paper_theme() +theme(legend.position =c(0.8, 0.2),legend.background =element_blank(),legend.title =element_blank(),axis.ticks.x =element_blank(),axis.text.x =element_blank(),panel.grid.major.x =element_blank(),panel.border =element_rect(color ="grey", fill =NA) ) +labs(x ="Subject", y ="Change from baseline",title ="Week 4 outcome by treatment")
Waterfall plot of week 4 outcome
To probe Law 1, what is the question addressed by this plot? It asks about the treatment effect after 4 weeks of treatment. Is this the right question? Let us assume for a moment that it is. Then a waterfall plot is not ideal for addressing it. Small treatment effects are difficult to discern, especially with an unbalanced randomization ratio. The audience must observe the distribution of color across the entire plot just to determine which treatment is more beneficial; this can become even more difficult with a larger sample size or more than two treatment groups. In Figure 1, one might see a treatment benefit, but how large is it and how certain of it are we? The popularity of waterfall plots is a mystery.
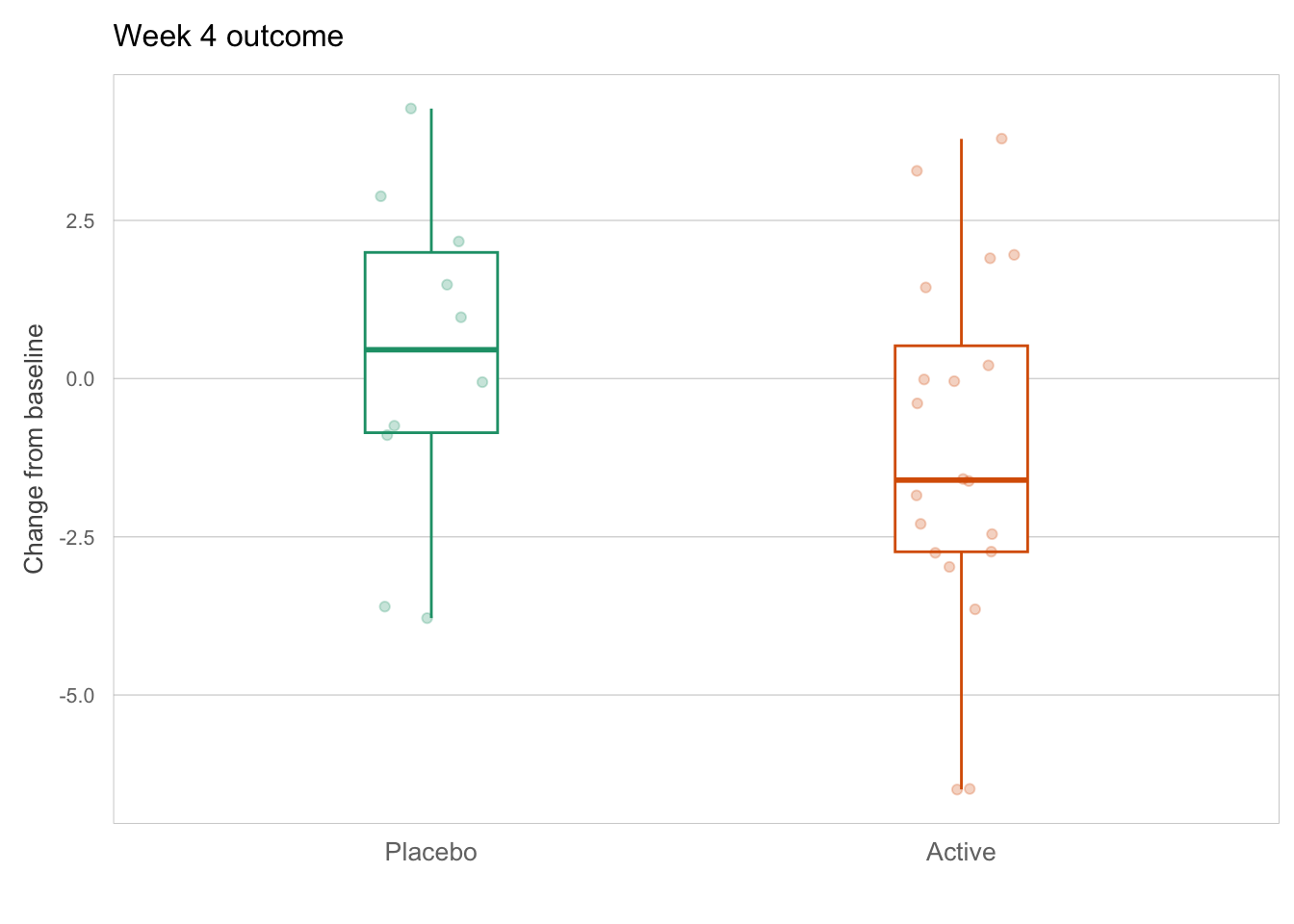
If we insist on week 4 as the only time point of interest, we could present overlaid density plots or side-by-side boxplots for a better appreciation of the difference in distribution between the two treatment arms. Figure 2 shows an example with the raw data points included, which is a much better alternative to Figure 1. The side-by-side placement facilitates the treatment comparison, and the plot is simple, familiar and uses minimal ink for what it shows. Graphical attributes (colors, font size, etc.) are easily readable.
ggplot(data = t4dat, aes(x = ztext, y = cfb, colour = ztext)) +geom_boxplot(width =0.25) +geom_jitter(alpha =0.25, width =0.1) +scale_colour_brewer(palette ="Dark2") +labs(x ="", y ="Change from baseline") +paper_theme() +theme(legend.position ="none") +labs(x ="", y ="Change from baseline",title ="Week 4 outcome") +theme(panel.border =element_rect(color ="grey", fill =NA, size =0.25),plot.title =element_text(size =12),axis.text.y =element_text(size =8),axis.text.x =element_text(size =10),axis.title.y =element_text(size =10),axis.ticks.x =element_blank(),panel.grid.major.x =element_blank() )
Boxplots of week 4 outcome
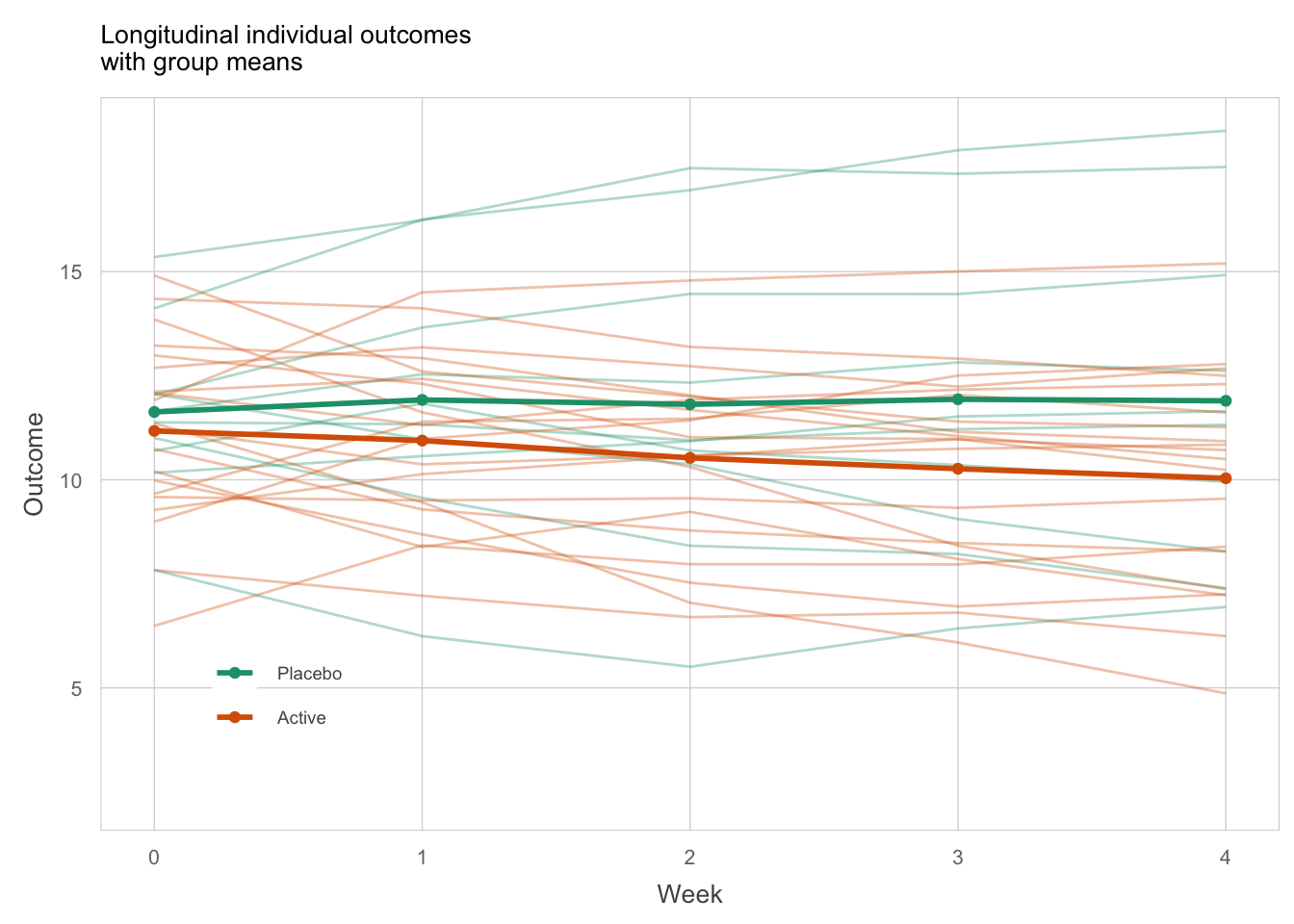
However, with such rich longitudinal data, it may be more informative to ask the question about the treatment effect during – not just after – the first 4 weeks of treatment. This is especially relevant in the early, more exploratory development phase (and it would be even more relevant if there were dropouts). As a rule, the recommended first step is to visualize the totality of the data. Figure 3 does this and includes means by treatment and time point. We see large inter-individual variability and overlap between the treatment groups. We also start to get an appreciation for the time-course of a mean effect. We see linear trajectories of the means over time, with the active arm appearing to improve and the placebo arm staying fairly constant. We cannot exclude that the apparent gap might continue to increase beyond 4 weeks of treatment. This plot, while doing little more than displaying the raw data, is already worth sharing with the project team. It facilitates a much richer understanding of the data than the previous two plots. It shows the data clearly i.e. Law 2.
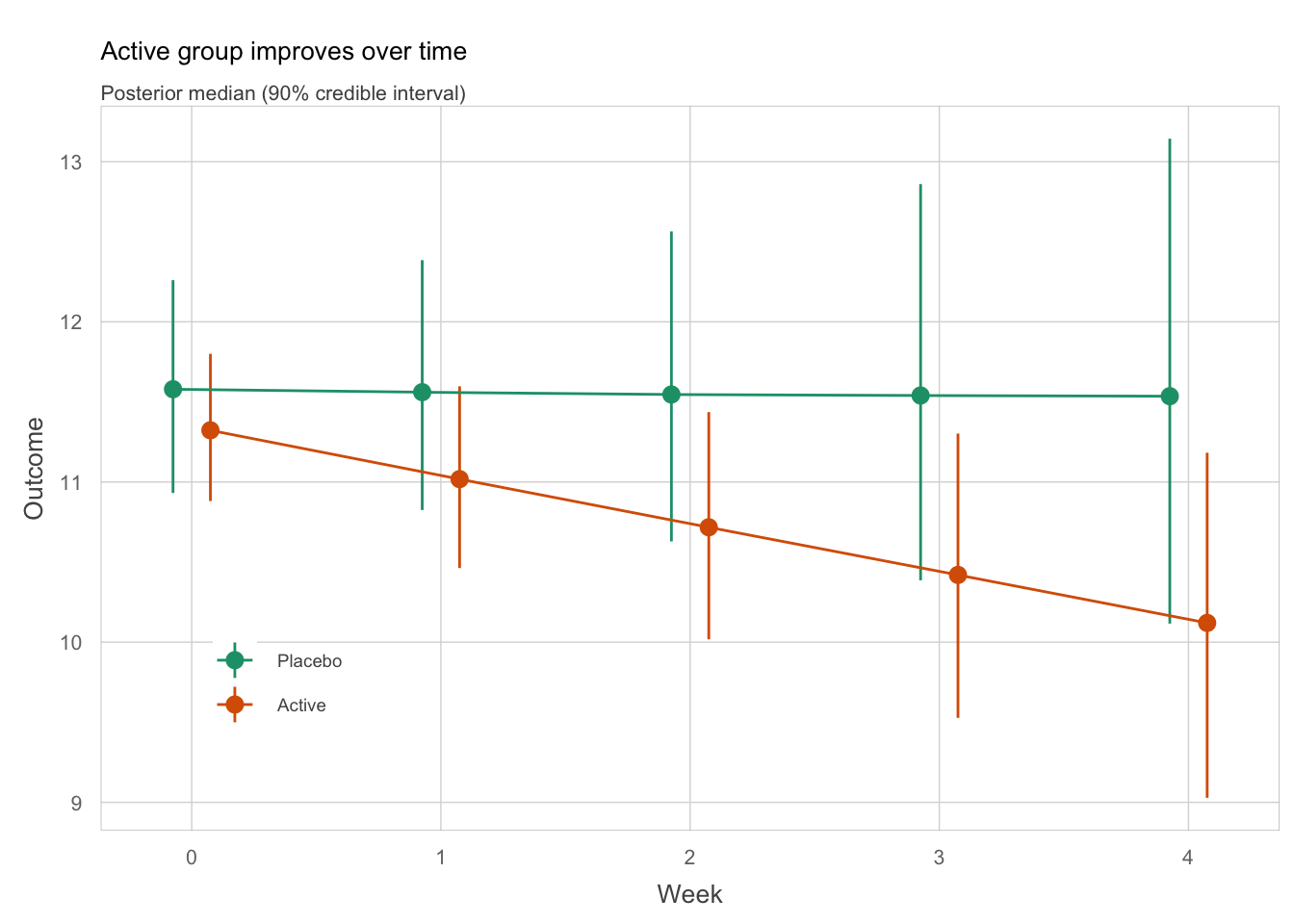
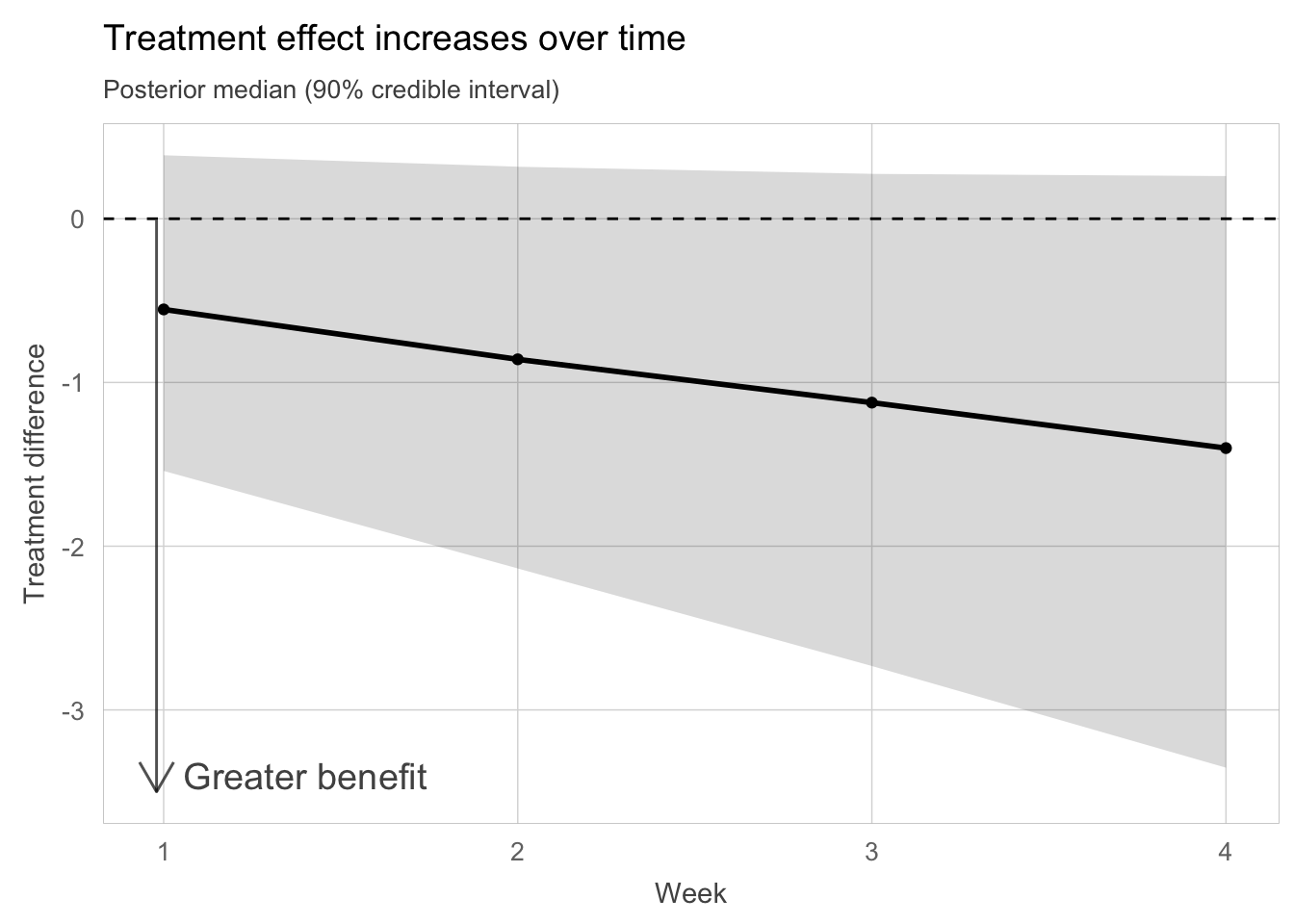
Depending on the goal of the analysis, we could stop here. But if we want to quantify the treatment difference while adjusting for important covariates, we should proceed with a statistical model. Based on Figure 3 a linear model appears appropriate. We fit a linear model with treatment, patient-specific intercept and slope, and we now also adjust for the baseline value of the primary endpoint and for any other important covariates. We can then visualize the data filtered through this model, omitting the raw data but displaying longitudinal point estimates and some form of uncertainty intervals for both treatment groups (Figure 4). This gets closer to the nature of a messaging graph, focusing directly on the results of our model. Optionally – and depending on the audience! – we could even go one final step further and display the treatment difference directly, as in Figure 5. This plot addresses the question about the treatment effect over time without requiring any mental arithmetic. We can read off approximate estimates for the treatment effect, and the level of confidence is easily appreciable from the added confidence band (which does include zero!). Appropriate and parsimonious annotations make the message even more obvious, Law 3, also through “effectively redundant” information (stating what can be seen).
It is worth emphasizing that this last plot should not be the only one generated, and probably not the only one shown either. Strongly reduced messaging graphs require a robust understanding of the underlying data, which can only be built through a workflow such as the one described above. Further, depending on the situation and the audience, they might be challenged as loaded or unscientific. (E.g., the apparently perfect linear trend in Figure 5 appears “unrealistic”.) It is therefore important to ensure and emphasize that this last plot derives from a model which (as every model) is intended to separate the signal from the noise, and that the choice of this model is justified by a thorough inspection of the data.
ppnd %>%filter(var =="Contrast"& time >0) %>%ggplot(aes(x = time, y =`50%`)) +geom_ribbon(aes(ymin =`5%`, ymax =`95%`), fill ="black", alpha =0.15) +geom_point(size =1.5) +geom_line(size =1) +geom_hline(yintercept =0, linetype =2) +labs(x ="Week",y ="Treatment difference",title ="Treatment effect increases over time",subtitle ="Posterior median (90% credible interval)" ) +geom_segment(aes(x =0.98,y =-0.01,xend =0.98,yend =-3.5 ),arrow =arrow(length =unit(0.02*234, "mm")),alpha =0.25 ) +annotate("text",label ="Greater benefit",x =1.4,y =-3.4,size =5,alpha =0.75 ) +paper_theme() +theme(panel.border =element_rect(color ="grey", fill =NA, size =0.25),plot.subtitle =element_text(size =10, color =rgb(0.3, 0.3, 0.3)) )